「顔」をデータにするということ
情報学と人文学が交わるところで
SPEAKERS
鈴木 親彦
群馬県立女子大学 / 人文情報学
美術史(イタリア・マニエリスム期の版画研究)から出版業界、そして人文情報学へと歩んできた研究者。CODH(人文学オープンデータ共同利用センター)在籍中に絵巻物などの「顔」を切り出して並べた「顔貌コレクション」を構築。「方法」を組み立てて資料を横断的に比較することに関心がある。
中村 覚
情報学 / デジタルアーカイブ
工学部のシステム創成学科出身。卒業研究で歴史資料のデジタル化に取り組んで以来、デジタルアーカイブの世界へ。「デジタル源氏物語」プロジェクトなどに携わる。人文系の専門家と組みながら、技術を適用しやすいデータをかたちにしていくことを得意とする。
美術史と工学。まったく違うルートから「人文情報学」の現場にたどり着いた二人の研究者が、「顔」をめぐる共同研究プロジェクトに参加している。鈴木親彦先生(人文情報学・美術史)と、中村覚先生(情報学・デジタルアーカイブ)。絵巻物の顔を切り出し並べた「顔貌コレクション」、テキストから「顔」の描写を機械的に抜き出すプロトタイプ——人文学の資料を情報技術で「データにする」とはどういうことか。そして、「描かれない顔」をどう扱うか。研究の現場で立ち上がっている難問を聞いた。
工学から人文学の資料へ
——今回は、この「顔」プロジェクトの中で、情報学の立場から携わっている鈴木先生・中村先生にお話を伺います。まず中村先生、この顔プロジェクトが始まる前から、永井先生の研究に接されていたのでしょうか。
はい。科研費の前に、ヒューマニティーズセンター(HMC)の共同研究に参加させていただいていました。ただ、永井先生とのご縁の出発点はもう少し前で、「デジタル源氏物語」というプロジェクトに遡ります。
——デジタル源氏物語。
はい。東京大学の情報基盤センターに就職してすぐの頃、学内のさまざまな機関が持っている貴重な資料を集約して検索できる仕組みを作る「東京大学デジタルアーカイブズ構築事業」に関わっていました。その中で、総合図書館が所蔵する源氏物語(「東大本」と呼ばれる)をデジタル化することになったんですね。
それで、せっかくデジタル化するのだから、もっと活用できないかということで、東大本や九州大学の本などを一元的に比較できる仕組みを作ろうという「デジタル源氏物語」プロジェクトが立ち上がりました。それがきっかけで、永井先生ともお知り合いになりました。
——中村先生はもともと工学部のご出身ですよね。なぜ歴史資料を扱うことになったのでしょうか。
卒業研究で配属になった研究室が、もともと旧船舶海洋工学科の流れを汲むシステム創成学科の研究室でして。最初は船の研究をするのかなと思っていたら、歴史資料のデジタル化に取り組むことになったんです。
というのも、指導教員の先生がすでに科研費を取って、ある歴史資料のデジタル化を進めていらっしゃって。それを情報技術で活用できないかというテーマを卒業論文でいただいたんです。歴史研究は本当に素人で、今もあまり詳しい自信はありませんが、それがデジタルアーカイブの世界に入ったきっかけでした。
——人文系だと、「人生をかけてこれを明らかにしたい」というようなテーマを探すことが多いですが、先生の場合は先輩の研究を引き継ぐ形でテーマが決まっていった、と。
そうですね。研究室の修士の先輩がすでに取り組んでいたテーマを引き継ぐ形で卒論で取り組むことになりました。工学系の研究室は、ある程度やることが決まっていて、それをいかに学生が進捗を出すかという「プロジェクト型」の組織であることが多い印象です。
ただ、人文学の知識は当然足りませんので、人文社会系研究科の鈴木淳先生の授業に出席したり、鈴木淳先生の研究室の学生さんと共同研究をしたりもしました。人文系の専門の方と一緒に研究するという形は、今思えば、学生時代から変わらないスタイルなんですね。
美術史から出版、そしてデジタルへ
——対照的に、鈴木親彦先生は美術史のほうから歩んでこられた方です。顔プロジェクトとの関わりの始まりを語るとすれば、どこからでしょうか。
私は結構、紆余曲折のあるキャリアでして。最初は、美術史をやっていました。修士論文は、イタリアのマニエリスム期の画家、パルミジャニーノによる版画をテーマに書きました。「2枚1組の版画で、構図は左右対称なのに、風の向きだけは左右対称になっていない」というような。
——そこから美術史の研究者になると思いきや、一般企業に就職されたそうですね。
出版関連の流通会社に就職し、いろいろな仕事をしていたのですが、その間に出版業界が大きく変わる出来事が起きました。2010年前後にiPadの発売やKindleの本格上陸があり、当時は「2010年は電子書籍元年」などといわれていました。「出版業界も、これからはデジタルの時代に適応しなくてはまずいことになる」と思いました。
それで、2010年に東大の文化資源学研究室に、社会人大学院生として修士課程に入学したんです。デジタルの波が押し寄せる中で、世の中に流通する情報はどういう文化的な位置づけを持つのか、ということを研究したくて。修士課程の途中で仕事を辞めて、研究一本に切り替えました。
——ちょうどその時期、大学の中でも変化があったんですね。
2011年から文学部で人文情報学の講義が本格的に始まりまして、デジタルと文化への興味から履修しました。ただし文学部からの履修者はあまり多くなかったですね。
2012年に博士課程に進学したのですが、そのタイミングで東大全体を横断する「デジタルヒューマニティーズ」の副専攻が開講されました。その中で「知の構造化センター」の講義を受講したんです。大量のテキストデータを構造化するという、現在のLLMにも通じる考え方の研究所でした。そこでお手伝いをする中で、人文学が情報学のツールを使うということに研究の軸が変わっていきました。
——そして博士課程の在学中に、今度は別の機会が訪れた。
博士課程在学中に、大学共同利用機関法人「情報・システム研究機構(ROIS)」に「データサイエンス共同利用基盤施設(DS)」が設置されました。その中に人文学のオープンデータを扱う「人文学オープンデータ共同利用センター(CODH)」が置かれることになったんです。
第1号の研究員を募集していたので応募したところ、情報学と人文学が両方分かる人間として採用していただけた。実際の拠点が国立情報学研究所(NII)の中にあったので、国立情報学研究所の研究員も兼ねることになりました。
「顔貌コレクション」が生まれるまで
——そのCODHで「顔貌コレクション(通称:顔コレ)」を作ったのですね。
はい。CODHでは、画像データを収集するツールが開発されていました。さまざまなデジタルアーカイブから画像の一部をデータとして切り出し、切り出したデータがどんなものか説明する「データのデータ」、つまり「メタデータ」を追記できるというものでした。これを使った人文学の実践的な研究を行うというのが私のタスクでした。
最初の1年は結構苦しかったのですが、最終的にたどり着いたのが、さまざまな作品に描かれた人物の「顔貌」——顔の部分だけを切り取って集め、メタデータを付与して検索できるようにするというアイデアでした。慶應義塾大学、国文学研究資料館、京都大学、国立国会図書館が所蔵する、国宝級・重要文化財級ではないものの、なかなか面白い、江戸時代の絵巻物や挿絵から顔を切り取ってきて、整理して検索できるサービスにしたんです。
——一級品ではない作品を対象にしたところが面白いですね。
そこがまさにポイントでした。一級品の作品は当然研究が蓄積されていますが、それ以外の膨大な作品たちにも、実は共通のルールで描かれた「顔」がある。それを俯瞰して見ることで新しい発見があるんじゃないかと考えたんです。
実際、これを作った時にGoogleの方が「面白そうだからデータセットにしませんか」と言ってくれて、機械学習用の「顔コレデータセット」も公開しました。
——そこから直接、この「顔」プロジェクトに繋がったということでしょうか。
私はもともと、特定の対象をマニアックに深掘りするタイプの人文学者ではなく、「方法」のほうが好きな人間なんですね。
ある資料を、研究に使いたい単位で切り取って、メタデータをつけて、横断的に比較する。顔に限らず、文字でも、文章の一部分でも、写真でも、この方法は使えるはずだ、と。で、その汎用的な方法論に、「いいですね!」と乗り気になってくれたのが、美術史学の髙岸輝先生でした。
——中世の絵巻物の専門家でいらっしゃいますね。髙岸先生とは、どんな取り組みをされたのですか?
中世の絵巻物に描かれた「僧侶と尼僧の顔」を集める、ということをやりました。
美術史をやっている人間からすると、基本的にどんなに下手な絵でも、「これは男性の顔」「これは女性の顔」と識別できるんですよ。ルールが決まっているからです。男性なら髭が生えているとか、烏帽子をかぶっているとか、きまりがある。
ところが、僧侶と尼僧だけはそうはいかない。男性も女性も、同じ姿になってしまうので、だったら、「描き手が男女の顔を描き分けようとする意図があったのかどうか、量の勝負で検証してみよう」と。その過程でいろいろ新しい発見があり、そこから永井先生のプロジェクトにもお声がけいただいたという流れです。
何でもデータになるという考え方
——お二人とも、まったく違うルートからこの場所にたどり着いたのですね。一方で、共通するのは「人文学の資料を情報技術で『データにして』扱う」というところですね。ここで、「データにする」とはどういうことか、もう少し詳しく教えてください。
デジタル画像が存在する時点で、ある意味それはもうデータではあるんです。ただ、それは「ただの画像」です。この画像のここに何が映っているのか、それは誰の顔なのか、いつの時代の何派の絵師が描いたものなのか——そういう説明情報をどんどん足していくことで、データが「リッチ」になっていく。
——その説明情報が「メタデータ」ということですね。
さらに、外部の別の資料との繋がり、「この資料は別の図書館のあの資料と関連している」というようなリンクが入ってくると、もっとリッチなデータになる。これは中村先生のご専門に近いですかね。
私からすると、人文学のあらゆる資料は、データになりえます。ただ、100人の研究者がいたら、1つの絵でも100通りの見方がある。顔の向き、髪型、色の使い方、衣装の特徴——それぞれの研究によって、どんな情報を付けたいかが全く違います。「データ」のあり方が、ひとつではないんです。
——確かに、理系の実験と比べると「データ」のイメージがずいぶんちがいますね。
そうなんです。私のもといた工学系の研究室でも、実験機器が大量のデータを出してくれる場面はありましたが、人文学の場合は、絵や文学資料から機械処理しやすいデータにする段階に大きなコストがかかる。それが、鈴木先生たちが苦労されているところですよね。
たとえば、巻物に描かれた顔を自動的に認識して切り出すこと自体は、AIでできてしまいます。でも、その顔が僧侶なのか武士なのか貴族なのか、男性か女性か、何時代の何派の絵師が描いたものか——そういった情報は、今のところ人間が一つ一つ手でつけるしかない。こういったデータを作るのは時間のかかる作業ですが、データを作るだけでは論文や著書に匹敵する成果としては認められにくく、従来の人文学のキャリアアップには繋がりにくいということがありました。
——構造的に難しい問題ですね。
これからはAIと一緒に研究していく時代です。AIを賢くするためには、人間が「これは殿様の顔だよ」「これは貴族だよ」と教えてあげないといけない。その教えるためのデータを作るコストが、文化系の資料では非常に高い。研究者の暗黙知を、メタデータの形に分解していく作業ですからね。もし十分に教育でき、事前作業部分を自動化できれば、研究全体のコストはぐっと下がる。人間が本当にやりたい解釈や分析の部分にもっと労力を費やせる可能性も出てきます。
ヨーロッパの「匂い」プロジェクトと、日本の「顔」
——中村先生は、このプロジェクトの中で実際にどんなことに取り組んでいらっしゃるんですか。
昨年度は、永井先生から「まずは、自由にいろいろ取り組んでみてください」と言っていただいたので、まずは関連する研究を調べることから始めました。文化資源のデジタル活用はヨーロッパが進んでいる部分が多くて、何か参考にできないかな、と探索していました。その中で「Odeuropa(オデウロパ)」というプロジェクトを見つけたんです。
——Odeuropa。匂いとヨーロッパの造語ですね。
ヨーロッパの歴史的な文献や絵画から「匂い」に関する情報を抽出して、データとして扱おうというプロジェクトです。たとえば、絵画の中でタバコを持っている部分を検出したり、テキストに出てくる匂いの種類や発生源を機械的に抽出したりする。
これを知って、同じアプローチを日本のテキストに応用できないかと考えました。匂いではなく、「顔」の描写で。
——香りから顔へ。発想の転換だと思いました。そのアイデアはどこから生まれたのですか。
Odeuropa自体は、別の研究者の方から「こういう取り組みがあるよ」と教えていただいたんです。で、並行してこの顔プロジェクトのことも考えていて、「これとこれを組み合わせたら面白いんじゃないか」と思いついたんです。
ただ、僕自身は、人文学的な「これをやったら面白いことが生まれる」というセンスはあまりないと思っています。むしろ、技術を適用しやすいデータが揃っているか、近くにレビューしてくださる専門の方がいるか、という観点で選ぶことが多いですね。
——実際に、ツールのプロトタイプも作られたとか。
はい。国立国会図書館の資料を対象に、テキストの中から「顔」の描写——たとえば表情や容貌に関する表現——を機械的に抽出して検索できるようにするアプリを試作しました。キーワードを入れると、その表現が出てくる文献を一覧できるというしくみです。
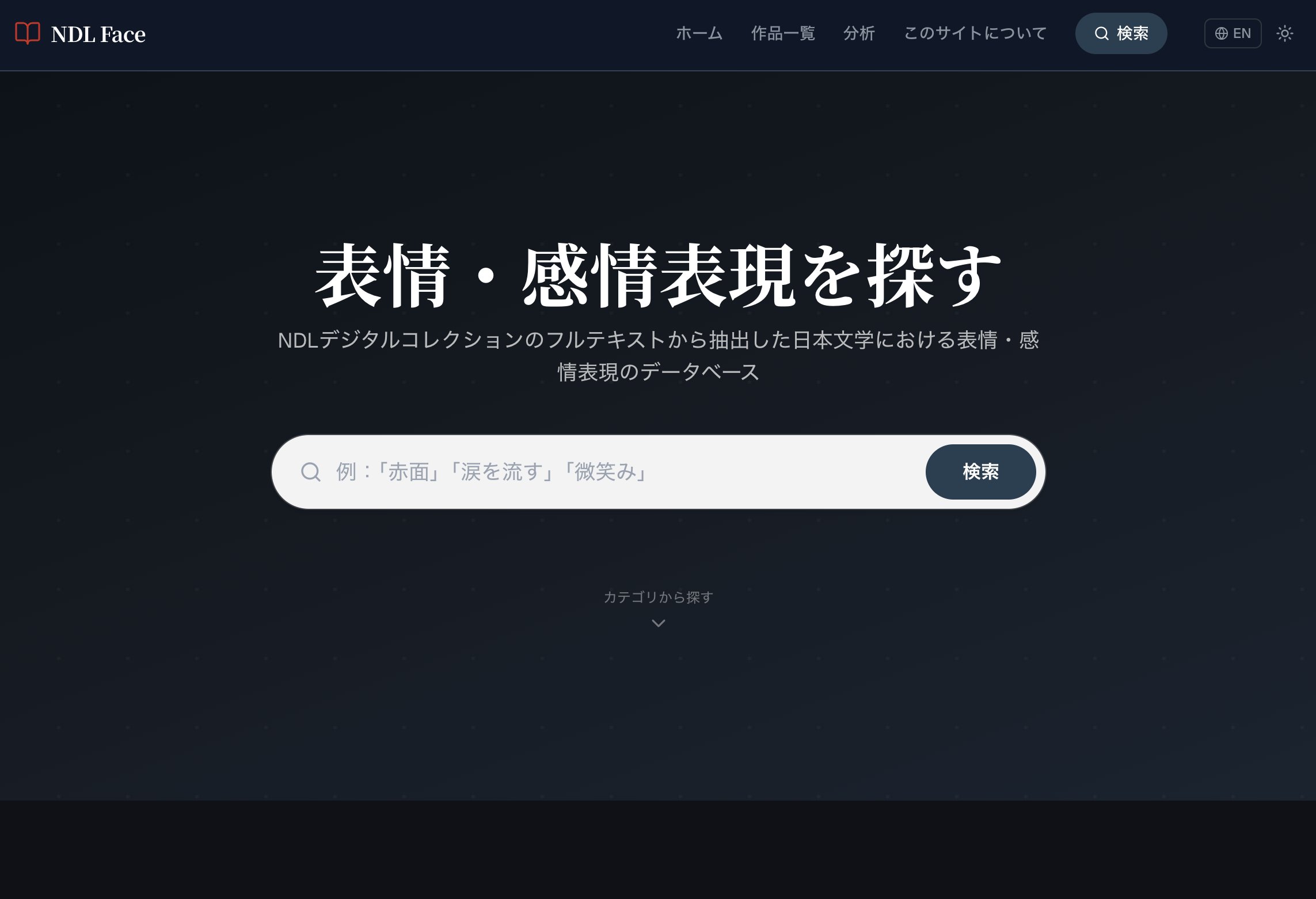 中村先生が試作したプロトタイプ「NDL Face」のトップ画面。「表情・感情表現を探す」というキャッチコピーが掲げられている。
中村先生が試作したプロトタイプ「NDL Face」のトップ画面。「表情・感情表現を探す」というキャッチコピーが掲げられている。
例えば、「赤面」と検索窓に入れると……
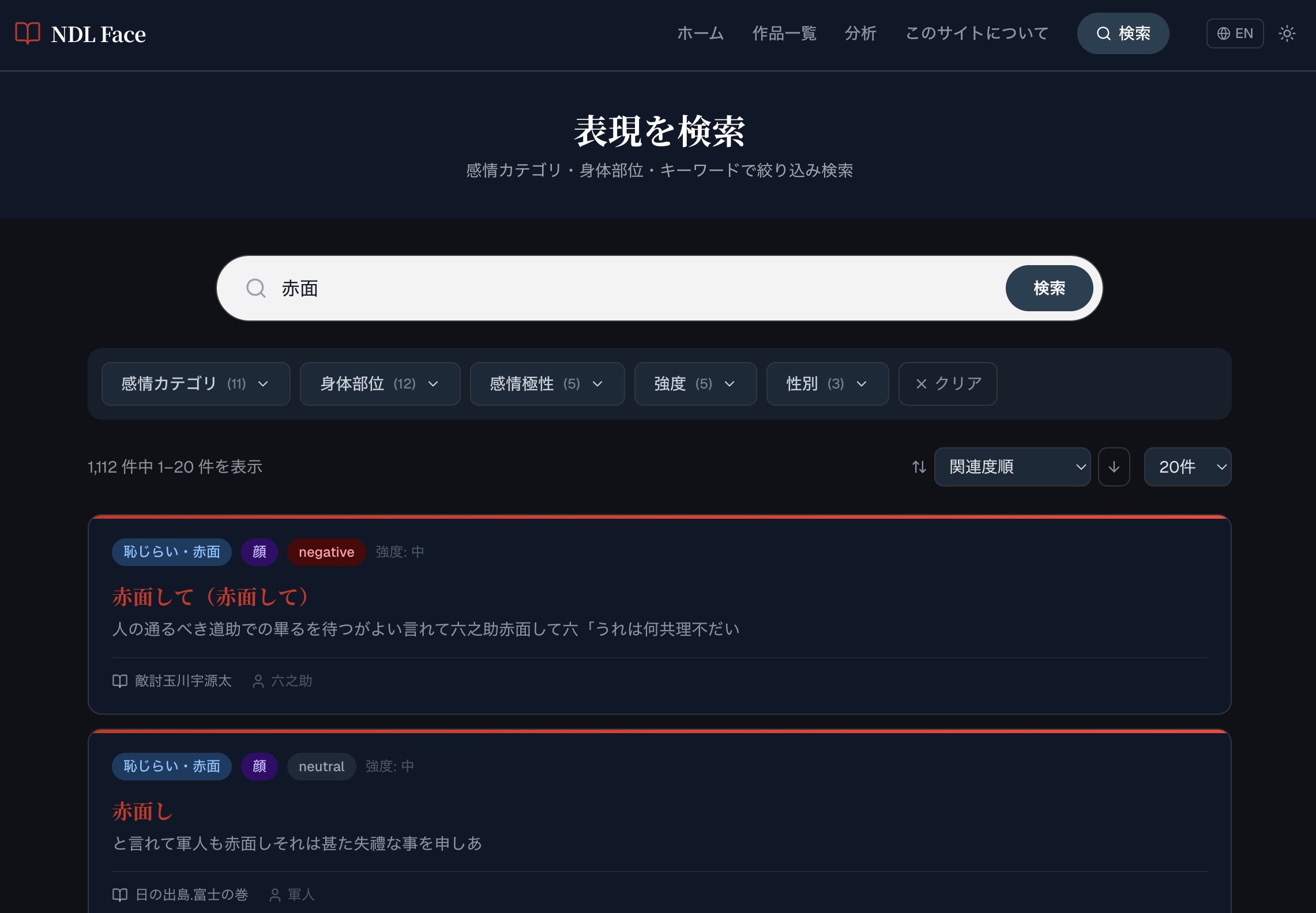 「赤面」で検索した結果画面。1,112件がヒットし、感情カテゴリ・身体部位・感情極性・強度などで絞り込みができる。
「赤面」で検索した結果画面。1,112件がヒットし、感情カテゴリ・身体部位・感情極性・強度などで絞り込みができる。
平安文学から近代文学まで、「赤面」という言葉が出てくる文章やせりふを一覧化してくれます。
——いま、検索結果をみて、面白いなと思いました。「赤面」といえば、私は太宰治『走れメロス』の最後の一文「勇者は、ひどく赤面した。」を思い浮かべるのですが、検索結果の画面には、例えば「拙者はなはだ赤面いたす」という武士のせりふがある。「赤面」にこんな用例があったんだ!と、初めて知りました。こうやって、一覧で見てみることで、新しい発見も生まれてきそうですよね。
まさにそういった形で、「こんなのどうでしょう?」と作ってみたツールを、まずはとりあえず専門家に触ってもらう、というケースが多いですね。「こういうことが情報技術を使えばできそうですよ」というプロトタイプを持っていって、専門の方にレビューをいただいてブラッシュアップしていく。
ただ、正直なところ、これが本当に永井先生や出口先生の研究に役立つかどうかは、これからディスカッションしていきたい、という段階です。
——プロトタイプを持っていく際に、何か心がけていることはありますか。
スライドで「こういうことができます」と説明するよりも、動くものを作って実際にお試しいただくようにしています。
人文系の先生方の専門知識をいかにプロンプトに流し込むか、というところが今後の重要なポイントだと思います。研究者がどういう粒度で見たいのか、何が分かったら嬉しいのか、そういう対話の内容を、プロンプトに落とし込んでいこうと考えています。
絵の「最小単位」としての顔
——鈴木先生のほうは、このプロジェクトの中でどんな動きをされていますか。
私は中村先生ほど技術力が高くないので、どちらかというと「ありもの」——すでに誰かが開発してくれたコードやツールを探してきて使う側の人間です。プロジェクトの中では、やはり同じ美術史畑の髙岸先生と一番よく話していますね。
先日も、京都大学の上田竜平先生のところで心理学的なアプローチに関する発表を聞いてコメントする役割をやりました。こうした新しいアプローチに触れると、「じゃあ次はどんなツールが使えるかな」と探しに行く。そういう形が多いです。
——何か具体的に取り組んでいることはありますか。
別のプロジェクトで、狩野派の絵師たちが持っていた「粉本【ふんぽん】」——絵を描くためのお手本帳のようなもの——をデータ化するということをやっているんですが、その過程で、このプロジェクトとの繋がりに気づいたんです。
美術史では、絵画を構成する要素の集合体を「画題」と呼びます。「画題」は美術史にとって重要なもので、複数の辞典類も整理されているのですが、データとして扱うときにちょっと曲者なんですね。
例えば、「松」は一つの画題です。さらに、「松が並んでいて、砂浜があり、波がある」となると「白砂青松」という画題にもなります。データ化してみると、画題どうしが複雑にオーバーラップするんですね。
——こうしてみると、画題のデータ化はかなり難易度が高そうです。専門家が見れば、小さな画題も、画題どうしが組み合わさった大きな画題も、同時に理解できてしまいますよね。
そうなんです。でもその中で、絶対に崩れない最小単位があることに気づいたんです。
それが「人物」なんですよね。この服装でこの顔をしていればこの人物である、というのは動かない。つまり、「顔」というのは、絵画をデータとして分析する際の最小単位になりうるんじゃないか。
そして、描かれている顔と、そこで描かれようとしているストーリーやキャラクター性は、最終的に切り離せないものとして現れてくるだろう、と。それをこの科研費プロジェクトと結びつけてデータ整理できないかな、というのが、今考えていることです。
「描かれない顔」をどうするか
——ところで、前回のインタビューで出口先生がおっしゃっていた「顔が描かれないパターン」の問題は、データの側からはどう見えるのでしょうか。
それは実は、顔貌コレクションを作った時からずっと直面している問題です。
「顔がない人」っていうのはいるんですよ。たとえば、高貴な女性は御簾の向こうにいて顔は絶対に描かないというのが、ある時期からルールになっている。じゃあ「顔のコレクション」にそれをどう入れるのか。
——「ない顔」をデータにする方法というのは、はたして存在するんでしょうか。
さらに言うと、綺麗な顔は描きやすいけれど、醜い顔は描きにくいという問題もあります。例えば、『源氏物語』の末摘花の巻の挿絵の例があります。荒れ屋に住んでいる末摘花を描いたものもあるにはあるんですけれど、むしろその後の、光源氏と若紫が一緒に絵を描くシーンもよく出てきます。光源氏が、末摘花の容姿に似せた女性の絵を描くくだりがありますよね。そのシーンを俯瞰で描いて、末摘花本人は描かないわけです。
描かれない末摘花のように、ストーリー上は存在するけれど描かれていない顔は、簡単に言うと画像データにならないわけです。それをデータとしてどう扱えばいいのかは、10年以上答えが出ていません。
今のお話を聞いて思ったのですが、顔貌コレクションにおいても「抽出できなかった顔がある」という事実自体を何かデータとして記述しておくといいのかもしれませんね。「ここに人は描かれているけれど顔は切り出せなかった」という情報があるのとないのとでは、後の分析が結構違ってくるんじゃないでしょうか。
なるほど。そのシーンにいるはずなのにいない、というのは、テキストを読めば分かりますよね。源氏物語だったら、テキストには登場人物としているんだけどシーンの絵にはいない、とか。ただ、画像データとして「ない顔」をどう入れるかは確かに難しい。コンテキストの話になりますね。
——文脈をデータでどう表現するか。新しいチャレンジですね。
一応、苦し紛れに、完全に隠れている顔——網笠をかぶった後ろ姿とか、女性の後ろ頭とか——は顔貌コレクションの中に入れてはいるんです。ただ、当初の目的からするとそれは「顔」じゃないんですよね。そういったデータを機械に学習させると、網笠を「顔」と認識してしまうリスクもある。まだまだやるべきことはたくさんあるものだと思います。
オープンであることの意味
——鈴木先生が先ほど、「ありもの」のツールを探してくると言われていました。人文情報学の研究者が開発したオープンソースのツールを活用する、ということですね。
そうです。今や、人文情報学の研究は世界中で行われています。日本語では開発されていなくても、他の言語圏で研究に使えるツールを探すと見つかる場合も多いですね。
中村先生がOdeuropaを見つけてくださったのと同じように、たとえば、画像の色味で絵画を評価するようなツールがアメリカの大学で共同開発されてオープンに公開されている、とか。そういうものを見つけると、「あの先生が言っていたあの研究に使えないかな」と考えますよね。
情報系の評価基準として、「作ったものが汎用的に使えるかどうか」「他の人が利用できる形になっているか」ということが重要視されているんですよね。ソースコードを公開して第三者が使えるようにするのは、オープンサイエンスの流れもありますし、公的な研究費で作ったものは第三者が使えるようにしましょう、という位置づけでもあります。
——人文学にとっては、オープンであること自体が必ずしも当たり前ではない、ということでしょうか。
ここが、私が感じている人文学のアンビバレントなところなんです。人文情報学の世界ではオープンはもう前提になっていますけれど、人文学一般で言えば、「この資料は自分しか見ていないから、自分のこの研究がすごいんだ」という価値観だって当然あります。見ること・見つけることが大変な資料を発見し、扱うことで唯一無二の研究となることもあります。
これはどちらか一方の在り方だけが正しいというものではありません。資料を扱う現場ではさらに難しい問題にもなり、その状況を知っている身からすると、さまざまな人文学者がオープンな姿勢で集まって「顔」という切り口でプロジェクトを進めていくこと自体に、大きな意味があると思っています。
これからの展望
——プロジェクトの折り返し地点にさしかかっていますが、これからどんなことをしていきたいですか。
1年目は自由にさせていただいて、先ほどお示ししたプロトタイプも作ることができました。この後は、専門の方に見ていただいてブラッシュアップしていきたい。
これまではテキスト中心の分析でしたが、鈴木先生のお話や出口先生の挿絵研究にあるような画像の分析と組み合わせて、テキストと画像の両面から——マルチモーダルに——「描かれない理由」や「描き方の変化」に迫れるような情報技術の応用を考えていけたらと思っています。
私は、これまで主に髙岸先生と画像の分析をやってきたのですが、いよいよテキストの話が本格的に始まるところです。近代以降はテキストと挿絵がセットで存在していますが、中世ではテキストと絵が別の世界として成立していることも多い。そのグラフィカルな部分とテキストが「顔」という要素でどう交差するのか、残り1年8ヶ月ほどの中で深めていけたら大きな成果が出ると思っています。
それから、先ほどふれたオープン性のことですね。人文情報学ではある種の前提条件となっていることが、人文学全般の研究に対してもオープンな成果として広がっていく可能性があります。この萌芽研究からそういう流れが立ち上がってくるのではと、とても期待しています。